Common pitfalls in deploying AI Agents to production
key challenges in deploying AI agents to production environment. I cover topics such as reliability, excessive loops, tool customisation, self-checking mechanisms, and explainability.


In this article I share what I have identified as the key challenges in deploying AI agents to production environment. I cover topics such as reliability, excessive loops, tool customisation, self-checking mechanisms, and explainability. If you strat to think that your AI Agents are tripping high and hallucinate, this article is definitely for you.
You will also find mitigation strategies that include rigorous testing, custom tool development, automated validations, transparent algorithms, and comprehensive AI Agents monitoring.
By implementing these solutions, businesses can significantly enhance the functional readiness and reliability of their AI Agents for production environments.
Key Takeaways
- Reliability: Ensuring consistent performance is the foremost challenge. Agents often only manage 60-70% reliability, while enterprises require at least 99%.
- Excessive Loops: Agents, especially in CrewAI and other frameworks, tend to get stuck in prolonged loops due to repeating processes or tool failures.
- Custom Tools: Customisable tools tailored for specific use cases are crucial for optimal agent performance.
- Self-Checking: Agents need mechanisms to verify their outputs, such as output tests, URL validations, and other prompting methods.
- Explainability: Providing context, sources or citations helps build user trust in the agent’s outputs.
- Debugging: Effective logging helps identify where an agent fails, making debugging more manageable and efficient.
Ensuring Your AI Agents Are Production-Ready: Addressing the Core Challenges
The promise of AI Agents transforming workflows and processes is vast. However, achieving a level where these agents are production-ready presents significant challenges. At BehavioCrew, our consulting services are crafted to help businesses navigate these challenges.
Here's a detailed rundown of the the core issues we frequently encounter and how you can tackle them moving on with your AI Agents deployment.
Reliability
When it comes to deploying AI agents, reliability is the major point of the discussion with my customers. From our extensive experience with various startups and larger enterprises, it’s clear that reliability remains the foremost challenge. I have grown on building systems where typical expectations hover around 99% reliability, but most agents can only muster approximately 60-70%. Ups...
Why does this matter? Imagine rolling out an software (aka AI Agent) that operates correctly only 70% of the time. You're left with the daunting task of a human manually verifying the output the rest of the time. This unreliability is a significant obstacle for achieving autonomy. The primary goal for AI agents should be to consistently deliver expected results without constant oversight. Thus, enhancing reliability must be at the forefront of every development effort.
This "lack of reliability", as we perceive it, is natural part of the LLM architecture as it is "just another" programmed statistical model. To go deeper into the topic I encourage you to read the paper: What’s the Magic Word? A CONTROL THEORY OF LLM PROMPTING or watch the interview with the authors:
Mapping GPT revealed something strange...
Mitigation Strategies
- Rigorous Testing: Implement extensive testing protocols that simulate various real-world scenarios. This helps in identifying weak points before deployment.
- Redundancy Mechanisms: Incorporate backup systems to take over during failures, ensuring uninterrupted operations.
- Error Handling: Equip AI Agents architecture (on front-end and back-end) with advanced error-handling capabilities to recover from faults without human intervention.
- Do NOT Update LLM to newest version: Every update of the LLM version brings new behaviours to the model. Continuously update and refine your algorithms and prompts to adapt to new features and improve stability over time. If it works, do not fix it - once smart person told me 😄
- Performance Monitoring: Employ continuous performance monitoring tools that flag inconsistencies in real-time, allowing for immediate correction.
Excessive Loops
A common pitfall lies in the tendency of hierarchical AI Agents to enter excessively long loops, which can drastically hinder performance. Whether it’s rerunning functions due to unsatisfactory intermediate results or getting caught up in unending processing cycles, these loops are a pervasive issue. It can run your LLM API bill to astronomical amounts.
In platforms like CrewAI, AutoGen and others this problem is particularly notable. Frameworks need mechanisms to detect and limit these loops. The providers of such frameworks for incorporated hard-coded limits on repeat actions, preventing such inefficiencies. Reducing and managing these loops not only conserves computational resources but also enhances the overall efficacy of the agent. But the open questions remain
- "If I hard-exit the loop will the result be high quality?"
- "Why Agents got into the loop"
Our implementation shows that more loops not only consume resources but also have high negative impact on the quality of the output as agents starting to run out of context and hallucination trip starts.
Mitigation Strategies
- Change your process flow to sequential: Instead of relying on the AI Agents Manager to organise tasks in the agents team, predefine the business process and run it sequentially including loops when needed
- Convert your prompts to CoT: Include guidance for an AI Agent on how you expect it to realise the activity, leaving it just enough space for own ideas.
- Divide the activity to smallest chunks possible: Hence it sounds easy finding the right balance between number of underlying tasks its tricky. It is good to ask LLM how it is planning the activity and then refine it manually with human input.
- Loop Detection Algorithms: Integrate algorithms designed to detect and terminate excessive looping automatically.
- Step Limit Configuration: Set predefined limits on the number of iterations an agent can perform, cutting off after a reasonable threshold.
- Fallback Protocols: Design fallback procedures that redirect the agent to feedback loop tasks when excessive looping is detected.
- Evaluation Metrics: Regularly evaluate the steps and measure the quality of the outcomes of the loops to understand and eliminate root causes. Quite often the loop is caused by a human error.
- Human Oversight: In critical stages of testing and then during operations, employ human oversight and integrate it in your AI Agents framework to supervise the agent’s operations until stability is ensured.
Please find real life example of how the unhandled loop mitigation loop looks like in practice. The example is from unhandled loop from Blog Post AI Writer for article about Commercial Cleaning:

Importance of Custom Tools
Leveraging tools effectively can make or break your AI agent’s utility. While general tools available in AI Agents frameworks are beneficial for initial setups, they always require significant customisation to fit specific needs. In our case the tool calls are always rewritten from scratch.
Creating your own tools tailored to your particular applications is crucial. These tools can handle specific data input/output, ensure meaningful data manipulations, and inform the agent appropriately during failures. For instance, a custom webpage parsing tool can read the webpage more effectively than a generic counterpart, ensuring relevant and timely information for your agents.
Mitigation Strategies
- Create your custom tools: Make sure that the tools you are using are processing only the data that you need. Avoid processing the unnecessary data as it might overflow the context window.
- Tool Optimisation: Optimize baseline tools to handle specific requirements of your applications effectively.
- Custom Tool Development: Invest in developing custom tools tailored to particular needs and scenarios.
- Version Control: Implement version control for tools to track changes and revert to stable versions if required.
- Agents Training: Provide training for AI Agents to give them examples on how to make the best use of customised tools.
- Integration Testing: Regularly test tool integration with agents to preempt and address compatibility issues.
- Be aware of the context window: If your toll produce large number of tokens that will use up context window, you will make LLM to loose its context and start hallucination trip.
Implementing Self-Checking Mechanisms
An autonomous agent framework must have a build in self-checking mechanism to validate its outputs. Without this, the reliability and accuracy of the agent become questionable. For an agent generating code, simple unit tests can suffice to confirm that code performs as expected.
In other contexts, agents need to verify URLs or cross-check data entries. Implementing these checks ensures the agent’s outputs are valuable and accurate. This self-validation process stands as a gatekeeper to prevent errant information from becoming actionable, maintaining the credibility and effectiveness of your AI solutions.
Mitigation Strategies
- Unit and Integration Tests: Regularly conduct unit and integration tests to validate outputs in various scenarios.
- Automated Validation: Deploy automated validation scripts that can run predesigned checks on outputs autonomously.
- Feedback Loops: Create feedback loops that allow the system to learn from errors and improve future performance.
- Third-Party Verification: Employ third-party verification tools to cross-check critical outputs.
- Continuous Improvement: Establish a continuous improvement framework to regularly refine self-checking mechanisms.
Enhancing Explainability
Providing explainability in AI outputs significantly boosts user trust. Agents need to demonstrate why a particular action or result was generated. Citations or source references are excellent ways to accomplish this.
Imagine receiving a generated report without understanding the rationale behind the figures. An explanation not only adds transparency but validates the decision-making process of the AI. Facilitating this kind of traceability in agent outputs ensures that end-users feel confident in relying on the AI’s recommendations.
Best practice is to store the raw data from the input, with proper indexing in RAG database and execute the verification checks on the produced content. Example of how this good implemented frameworks looks like in working see our AI Reports Agent output: Report of the the Danish Economy
Mitigation Strategies
- Store the raw input data in RAG: Utilise the checks on produced content by comparing RAG data with LLM output as part of your framework.
- Citations and References: Integrate functions that automatically add citations and references to the outputs.
- Data Provenance: Track and store data provenance to provide insights into the decision-making process.
- User Interfaces: Build user-friendly interfaces that present explainability features clearly.
- Transparent Algorithms: Use transparent algorithms that make it easier to understand how decisions are made.
- Documentation: Maintain comprehensive documentation to assist users in understanding agent workings.
Efficient Debugging
Debugging is an often-overlooked aspect that’s critical for refining AI agents. Logging mechanisms that track decisions and outputs help identify where things go awry. This intelligence allows developers to pinpoint failures effectively and streamline corrections.
At times, agents don’t require advanced decision-making. For simpler sequences, direct coding bypasses the need for complex frameworks, making development more straightforward and robust. Regularly reviewing and assessing these decision points ensures you retain control and oversight over your AI’s operations.
Mitigation Strategies
- Comprehensive Logging: Set up comprehensive logging to capture valuable data at each decision-making point.
- User-Friendly Debugging Tools: Utilise user-friendly AI debugging tools that simplify the error detection process.
- Failure Analysis: Regularly conduct failure analysis to identify root causes and preventive measures.
- Real-Time Monitoring: Implement real-time monitoring systems that alert teams to issues immediately.
- Development Standards: Adhere to strict development standards to minimise bugs and streamline debugging efforts.
In my projects I am using LangSmith which example screen you can find below:
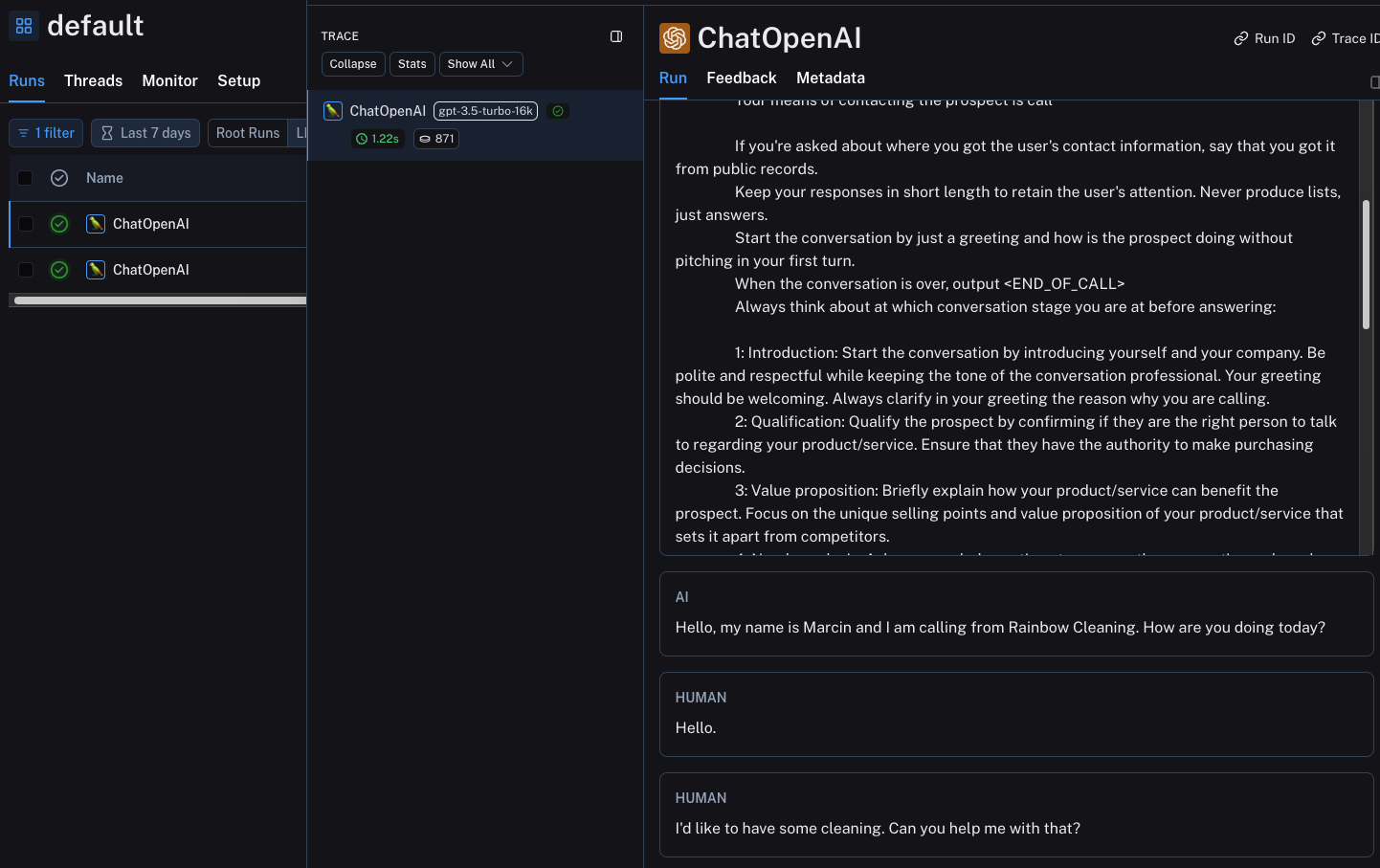
Selection of Technology Stack for AI Agents Deployment
Choosing the right technology stack is critical for the successful deployment of AI agents. The technology stack affects everything from development speed and integration capabilities to performance and scalability. An optimal stack ensures that the deployed AI agents are robust, efficient, and maintainable.
The challenge I was facing for quite some time, and number of trial and error attempts, was
- How to make the modern front end (NextJS) work fast with backend AI services which are typically in python
- How to create the deployment architecture that allows to bundle the backend and frontend solutions.
Here you can see the model architecture I have build, that solves most of the issues described in the article:
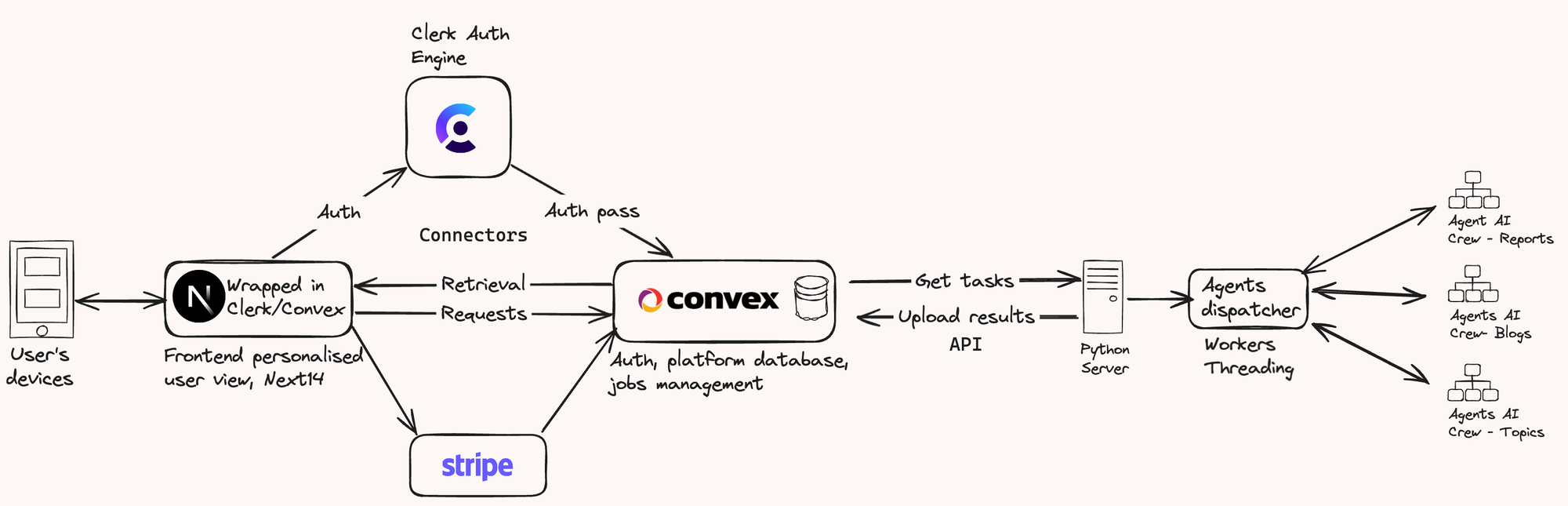
Mitigation Strategies
- Framework Agnosticism: Consider adopting a modular approach to remain flexible and adaptable to future technological advancements.
- Scalability Assessments: Ensure that the chosen technologies can scale to handle increased load and complexity and number of users as the project grows. Be careful with server-less solutions as they tend to generate costs quite fast.
- Compatibility Testing: Conduct thorough compatibility tests between different components of the stack to avoid integration issues. Sometimes using the API endpoints brings more benefits than boilerplate SDK for certain applications, as you might need complexities that SDK offers.
- Performance Benchmarking: Regularly benchmark performance metrics to ensure the stack meets the required standards.
- Community and Support: Choose technologies with strong community support and documentation to facilitate smoother development and troubleshooting.
Summary
By addressing these core areas, businesses can significantly improve the functional readiness of their AI agents. At BehavioCrew, we specialise in transforming these theoretical insights into practical, actionable strategies that ensure your AI agents are not just functional but exemplary.
Frequently Asked Questions
Q1: How critical is reliability in AI agent deployment? Reliability is paramount. Agents need to operate correctly nearly all the time to be truly useful and autonomous. Most enterprises expect at least 99% reliability.
Q2: What causes AI agents to get stuck in loops, and how can this be fixed? Agents often loop due to unsatisfactory intermediate results or tool failures. Solutions include setting hard limits on repeated actions and improving tool efficacy and customisation.
Q3: Why is customising tools so important in AI agent development? Custom tools tailored to specific needs ensure that agents handle data optimally, perform accurate checks, and deliver meaningful outputs consistently.
Q4: What are self-checking mechanisms, and why are they necessary? Self-checking mechanisms help agents verify their outputs for accuracy. This prevents errors from slipping through and ensures the reliability and credibility of the agent’s functions.
Q5: How does explainability enhance AI agent outputs? Explainability builds user trust by showing the rationale behind decisions. Citations and reference points make outputs transparent, reliable, and understandable.
Q6: How can effective debugging enhance AI agent performance? Effective logging and monitoring help identify failure points, making it easier to correct issues and refine the agent’s operations. This process is crucial for maintaining high performance and reliability.
Ready to make your AI agents production-ready? Get in touch with BehavioCrew today and let’s enhance your AI capabilities together!



